Coding comparison query
The coding comparison query compares coding by two users to measure 'inter-rater reliability'—the degree of coding agreement between them. Agreement is measured by two statistical methods:
- Percentage agreement: the number of content units on which coders agree (to code or not to code), divided by the total number of units—reported as a percentage.
- Cohen's kappa coefficient: a statistical measure that takes into account the amount of agreement expected by chance—expressed as a decimal in the range –1 to 1 (where values ≤ 0 indicate no agreement, and 1 indicates perfect agreement).
You can select specific codes or cases for comparison, in selected data files, datasets, externals and/or memos. You can also select groups of codes or files by identifying folders, static sets or classifications they belong to.
It is possible to compare coding between groups of users, however, standardly, comparisons are made between individual coders. If comparing groups, content is taken to be coded if at least one member of a group coded it. Coders are identified by their NVivo user profiles User profiles.
Comparisons can be run for text coding in data file documents (including PDFs), datasets, externals, memos, codes and cases. Coding in picture, audio and video files cannot be compared. Region coding in PDFs cannot be compared.
You can select characters, sentences or paragraphs as the unit of comparison:
-
Characters: Individual text characters in each code reference are used for comparison. This option provides the most accurate comparison in terms of the number of words coded.
-
Sentences: Coding of whole sentences is compared. If any characters in a sentence are coded, then the entire sentence is treated as coded. The query treats all sentences equally, regardless of length.
This option may be best if you know that all, or most, coding references in a project are complete sentences. If each sentence contains one complete concept, claim, opinion, decision etc. then your results may be more meaningful comparing sentences rather than characters—the concepts, claims, etc. are likely to be expressed in different numbers of words.
-
Paragraphs: Coding of whole paragraphs is compared. If any characters in a paragraph are coded, then the entire paragraph is treated as coded. The query treats all paragraphs equally, regardless of their length.
This option may be best if you know that all, or most, coding references in a project are complete paragraphs. If each paragraph contains one complete concept, claim, opinion, decision etc. then your results may be more meaningful comparing paragraphs rather than characters or sentences—the concepts, claims, etc. are likely to be expressed in different numbers of words.
You can save query configuration settings to run the same query at a later time, when more coding has been done. Queries are saved under Queries / Query Criteria in the Navigation View.
You cannot save query results in NVivo, however you can export them to other applications (e.g. Excel) to save. Export query results
Run a coding comparison
- On the Explore tab, in the Queries menu select Coding Comparison.
- For Search in, select the files within which you want to compare the coding:
- Files and Externals: all data files and externals, but not memos
- Selected Items: selected data files, externals and/or memos
- Selected Folders or Static Sets: all data files, externals and/or memos in selected folders and/or static sets
- Files with Classifications: all data files, externals and memos with selected file classifications
- For Coded to, select the codes or cases that you want to compare:
- All Codes: coding to all codes and cases in the selected files
- Selected Codes: coding to specific codes and/or cases in the selected files
- Codes in Selected Static Sets: all the codes and cases included in selected static sets
- Cases with Classifications: all the cases with selected case classifications
NOTE: If you include an aggregate code in the scope of a query, content coded to it and its direct children is included in the results. Aggregate codes
- For User Group A and User Group B, click
 to select the users whose coding you want to compare (recommended to compare individual coders). If you include more than 1 user in a group, any coding carried out by any of the users in the group counts towards the comparison.
to select the users whose coding you want to compare (recommended to compare individual coders). If you include more than 1 user in a group, any coding carried out by any of the users in the group counts towards the comparison. - Select whether you want the calculations to be based on characters, sentences or paragraphs (see above).
- To save the query settings, check Save Criteria at the top of the dialog box. Name the query and optionally provide a description.
- Click Run Query at the top of the Detail View.
Query results are displayed in the Detail View (see below).
Coding comparison results

Coding comparison results are displayed in two views in the Detail View: statistical results (this section) and a copy of all the content in the query showing the coded sections highlighted—see View coding agreement or disagreement below.
1 Overall, unweighted, kappa coefficient for all the codes and files queried. ('Unweighted' means that each file in the query contributes equally to the score, regardless of file size. This value is not provided 'weighted'.)
2 The codes and cases being compared—expand to see the files that had content coded to the code/case.
3 Files where the code or case was coded, with itemized statistics.
4 The file size, measured as the number of characters, sentences, or paragraphs, depending on the setting used.
5 The kappa coefficient for each code or case over the full scope of the query, or for each code or case per file (for expanded codes/cases).
6 These columns show percentage agreement:
- Agreement Column = sum of columns A and B and Not A and Not B
- A and B = the percentage of content coded to the selected code by both Group A and Group B
- Not A and Not B = the percentage of content coded by neither Group A nor Group B
7 These columns show percentage disagreement:
- Disagreement Column = sums of columns A and Not B and B and Not A
- A and Not B = the percentage of content coded by Group A and not Group B
- B and Not A = the percentage of content coded by Group B and not Group A
8 Display results with either:
- Unweighted Values Files are treated equally (regardless of size) when calculating the overall results for each code/case.
- Weighted Values File size is taken into account when calculating the overall results for each code/case. For example, if using paragraphs as the unit for comparison, a document with 10 paragraphs would contribute 5 times more than one with 2 paragraphs.
9 Select the Show coding comparison content check box if you want to see the data content where there is agreement or disagreement (see below).
View coding agreement or disagreement
This view shows the text in the scope of the query. The text is highlighted corresponding to 'coded by both coders' and 'coded by one coder but not the other'.
Check Show coding comparison content to view.
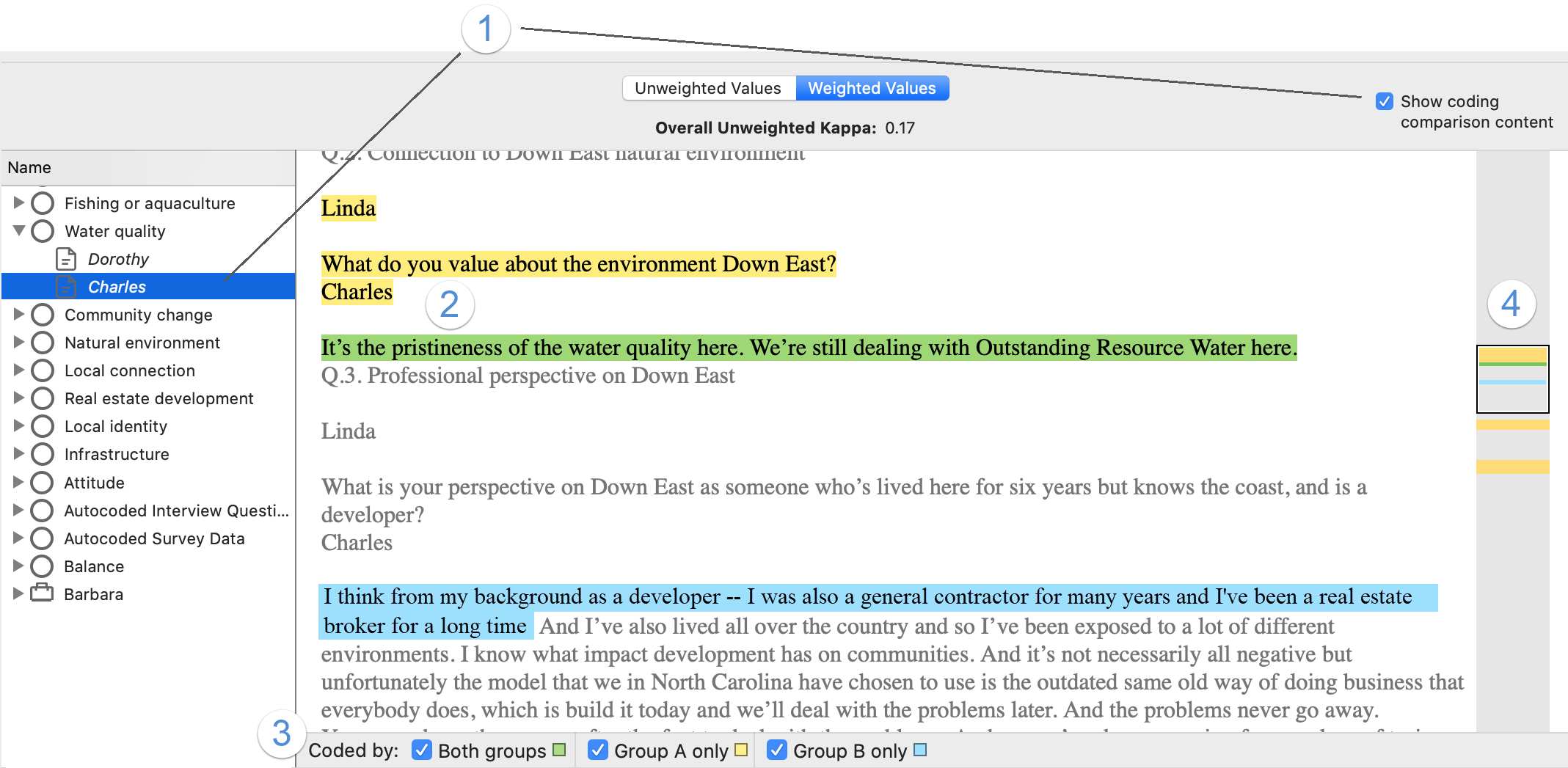
1 Select a code or file in the query results and then check Show coding comparison content to display the content pane. Alternatively, double-click the code or file.
Once the coding comparison content pane is open, click on another code or file in the left-hand pane to see its content.
2 Colored highlighting indicates text coded to the currently selected code or case:
- green: coded by both groups (Agreement)
- yellow: coded by Group A only (Disagreement)
- blue: coded by Group B only (Disagreement)
Text that was not coded by either group is displayed as grey text (Agreement).
NOTE Highlighted areas may include text that was not actually coded if the query used sentences or paragraphs as the unit of comparison. The wholes of partially coded sentences or paragraphs are used for coding comparison under these settings.
3 Show or hide highlighting.
4 Use the colored bars in the scroll bar to quickly see where there is agreement and disagreement. Click in the bar or scroll to navigate.
How is percentage agreement calculated?
NVivo calculates percentage agreement for each combination of code or case and file.
Percentage agreement is the percentage of file content (measured in characters,
For example, in a document with 1000 characters where:
- 800 characters have not been coded by either user
- 50 characters have been coded by both users, and
- 150 characters have been coded by only one user
the percentage agreement is (800 + 50) ÷ 1000 = 85%, because both users 'agree' about 850 of the characters.
How is the Cohen kappa coefficient calculated?
Cohen’s kappa is widely used to quantify the level of inter-rater agreement between two raters (i.e. coders). The formula calculates the agreement between two coders and then adjusts for agreement that would happen by chance.
The formula is: κ = P0 – Pe / 1 – Pe
where P0 is the amount of agreement between two coders (equivalent to the 'percentage agreement' calculated by NVivo) and Pe is the probability of chance agreement.
The formula can be illustrated by the following table, where:
- Pyy is the proportion of content that both coders assigned to a code
- Pyn is the proportion that coder 1 assigned to the code and coder 2 did not
- Pny is the proportion that coder 2 assigned to the code and coder 1 did not
- Pnn is the proportion that neither coder coded to the code.
The sum of these proportions is 1: Pyy + Pyn + Pny + Pnn = 1
| Coder B | |||
| Assigned code | Did not assign code | ||
| Coder A | Assigned code | Pyy | Pyn |
| Did not assign code | Pny | Pnn | |
The observed agreement, P0 is: Pyy + Pnn
The probability of chance agreement, Pe is: (Pyy + Pyn) × (Pyy + Pny) + (Pny + Pnn) × (Pyn + Pnn)
Two coders coded 100 excerpts in the proportions shown in the table:
| Coder B | |||
| Assigned code | Did not assign code | ||
| Coder A | Assigned code | Pyy = 40/100 = 0.4 | Pyn = 20/100 = 0.2 |
| Did not assign code | Pny = 10/100 = 0.1 | Pnn = 30/100 = 0.3 | |
The observed agreement P0 is: Pyy + Pnn = 0.4 + 0.3 = 0.7
(Both coders coded the same 40 excerpts and didn't code the same 30 excerpts, so they agree on 70 of the 100 excerpts.)
The probability of chance agreement is:
Pe = (Pyy + Pyn) × (Pyy + Pny) + (Pny + Pnn) × (Pyn + Pnn)
= (0.4 + 0.2) × (0.4 + 0.1) + (0.1 + 0.3) × (0.2 + 0.3)
= (0.6 × 0.5) + (0.4 × 0.5)
= 0.3 + 0.2
= 0.5
Inserting the values for P0 and Pe in the formula:
κ = P0 – Pe / 1 – Pe
= 0.7 – 0.5 / 1 – 0.5
= 0.2 / 0.5
= 0.4
The kappa coefficient for this example is 0.4, indicating a 'fair' or 'moderate' degree of inter-coder agreement (see next section).
You can see further examples of kappa coefficient calculations by downloading this Excel spreadsheet: Coding Comparison Calculation Examples spreadsheet.
Interpreting kappa coefficients
If two users are in complete agreement about which content to code in a file, then the kappa coefficient is 1. If there is no agreement other than what could be expected by chance, the kappa coefficient is ≤ 0. Values between 0 and 1 indicate partial agreement.
Different authors have suggested different guidelines for interpreting kappa values, for example (from Xie, 2013):
| Landis & Koch (1977) | Altman, DG (1991) | Fleiss et al (2003) | |||
|---|---|---|---|---|---|
| κ | Strength of agreement | κ | Strength of agreement | κ | Strength of agreement |
| 0.81–1.00 | excellent | 0.81–1.00 | very good | 0.75–1.00 | very good |
| 0.61–0.80 | substantial | 0.61–0.80 | good | 0.41–0.75 | fair to good |
| 0.41–0.60 | moderate | 0.41–0.60 | moderate | < 0.40 | poor |
| 0.21–0.40 | fair | 0.21–0.40 | fair | ||
| 0.00–0.20 | slight | < 0.20 | poor | ||
| < 0.00 | poor | ||||
Kappa vs. percent agreement
Kappa values can be low when percentage agreement is high. For example, if two users code different small sections of a file leaving most content uncoded, the percentage agreement is high, because there is high agreement on content that should not be coded. But this situation is likely to occur by chance (i.e. if the coding was random), and so the kappa coefficient is low.
Conversely, if most of a file is not coded but there is agreement on the content that is coded, then percentage agreement is again high, but now the kappa value, too, is high, because this situation is unlikely to occur by chance.
All kappa coefficients are 0 or 1
If all the kappa values in a query are 0 or 1 it may indicate that one of the two users being compared has not coded any of the selected files to the selected codes, i.e. you may have selected the wrong files, codes, or coders for the query.
NORA MCDONALD, SARITA SCHOENEBECK, ANDREA FORTE (2019). Reliability and inter-rater reliability in qualitative research: Norms and guidelines for cscw and hci practice. ACM Hum.-Comput. Interact, 39(39), Article 39, 23.
McHugh, M. L. (2014). Interrater reliability; the kappa statistic. In X. Lin, C. Genest, D. L. Banks, G. Molenberghs, D. W. Scott, & J.-L. Wang (Eds.), Past, present, and future of statistical science (pp. 359–372). Chapman and Hall/CRC. https://doi.org/10.1201/b16720-37
The New Stack. (2020). Cohen’s kappa: What it is, when to use it, and how to avoid its pitfalls - the new stack. https://thenewstack.io/cohens-kappa-what-it-is-when-to-use-it-and-how-to-avoid-its-pitfalls/
Vries, H. de, Elliott, M. N., Kanouse, D. E., & Teleki, S. S. (2008). Using pooled kappa to summarize interrater agreement across many items. Field Methods, 20(3), 272–282. https://doi.org/10.1177/1525822X08317166
Xie, Q. (2013) Agree or Disagree? A Demonstration of An Alternative Statistic to Cohen’s Kappa for Measuring the Extent and Reliability of Agreement between Observers. Conference presentation at Federal Committee on Statistical Methodology Research Conference, Washington, DC, November 4-6 https://nces.ed.gov/FCSM/pdf/J4_Xie_2013FCSM.pdf